
In this blog, the Austrian Institute of Technology and IBM Ireland provide an overview of COPKIT’s Natural Language Processing tools to extract structured information such as named entities, the relations between them, and the events from unstructured dark-net market advertisement and forum texts.
Darknet markets (DNMs) and associated forums provide online digital platforms for illicit activity such as trafficking of weapons, drugs, or hacking tools or guides for digital fraud. In the last decade, cryptocurrencies (e.g., bitcoin, altcoins) have supported illicit activities on the DNMs, allowing sellers to remain anonymous by concealing the financial transactions.
In order to extract usable knowledge from DNMs, data needs to be acquired and analysed which can be challenging due to the nature of how these markets operate. The markets can disappear quickly on the suspicion of being monitored by Law Enforcement Agencies (LEAs). On the data front, the amount of information and the number of illegal trading goods are unmanageably large, so the investigative and strategic analysts within the LEAs need tools for automatic extraction of knowledge from the unstructured large text data.
COPKIT’s solution
The COPKIT project has developed three distinct but related components that can help LEAs to automatically extract information for unstructured and semi-structured text data from the sources such as DNMs and DNFs (Darknet Forums). In particular, three components are developed:
- Named Entity Recognizer (CKNER).
- Relationship Extraction (CKRELEXT).
- Moment Recognizer as event extraction (MoRec).
There are generic challenges that had to be addressed during the development of these components in the COPKIT project. The first challenge was the lack of labelled data and the second was due to the specific characteristics of the texts published on DNMs. The most outstanding difference compared to standard corpora is that the data is not always structured in sentences, or paragraphs, and grammar and syntax are not always strictly followed.
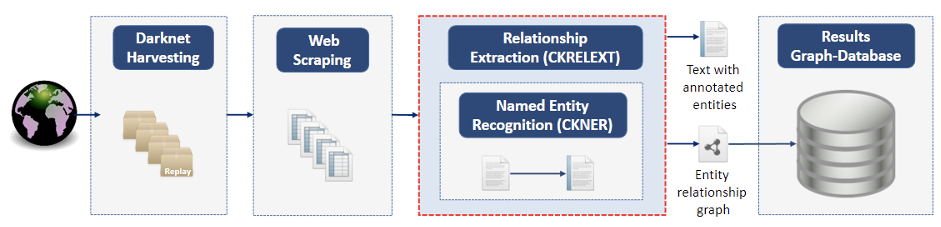
Figure 1 Process flow for CKNER and CKRELEXT
Named Entity Recognition (NER) is one of the typical Information Extraction tasks in Natural Language processing. The goal is to identify selected information elements, so called Named Entities (NE).Due to the unavailability of labelled data semi-supervised approaches were adapted to detect project use-cases specific entities such as weapons, drugs, and Crime-as-a-Service (CaaS) related entities such as carding, hacking, etc.
Relationship Extraction is one of the classical NLP tasks which aims at extracting semantic relationships from unstructured or semi-structured text documents. In COPKIT, the relationship extraction was implemented as a rule-based and pattern matching approach using shallow linguistic features. The CKRELEXT component takes individual text paragraphs (e.g. from darknet market advertisements) as input and produces a graph for this text without taking the context (darknet market crawl) into consideration.
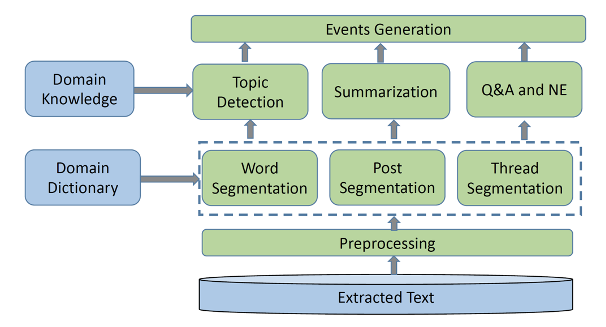
Figure 2 Process flow for MoRec
The MoRec component enables LEA analyst to understand the forum discussions in the knowledge discovery phase. The component adds value to an LEA’s analyst investigation by processing the unstructured discussion text among DNM members and extracting knowledge in terms of events. The events can be defined and configured in the component depending on the use-case under investigation.
The details of COPKIT’s information extraction components can be seen in the related webinar video.
For more information and updates, follow us on Twitter, LinkedIn and Facebook and feel free to contact our team at copkit@copkit.eu.
